
탐색이란?
- 컴퓨터에 저장한 여러 개의 자료중에서 원하는 자료를 찾는 작업
- 탐색키(항목과 항목, 자료들을 구별하여 인식할 수 있는키)를 가진 항목을 찾는 것
- 컴퓨터가 가장 많이 하는 작업 중의 하나
- 탐색을 효율적으로 수행하는 것이 매우 중요하다
- 원소를 삽입/삭제 할 위치 찾기 위해 검색 연산을 수행
- 배열, 연결리스트, 트리, 그래프 등 탐색을 위하여 사용되는 자료구조
수행위치에 따른 분류
- 내부 검색 : 메모리내의 자료에 대해서 검색 수행
- 외부 검색 : 보조 기억 장치에 있는 자료에 대해서 검색 수행
검색방식에 따른 분류
- 비교 검색 : 검색 대상의 키를 비교하여 검색(순차검색, 이진검색, 트리검색)
- 계산 검색 : 계수적인 성질을 이용한 계산으로 검색(해싱)
맵 or 딕셔너리
- 자료를 저장하고 탐색키를 이용해 원하는 자료를 빠르게 찾을 수 있도록 하는 탐색을 위한 자료구조
- 맵은 탐색키와 탐색키와 관련된 값의 2개 필드를 가진 키를 가진 레코드 or 엔트리로 구성
- key : 레코드를 구분할 수 있는 탐색키(사람의 이름)
- value : 탐색키와 관련된 값(주소나 전화번호)
- 키-값의 쌍으로 이루어진 이진트리의 집합으로 테이블에 저장
선형검색(순차탐색)
- 정렬되지 않고 일렬로 나열된 자료를 처음부터 마지막까지 순서대로 하나씩 검색
- 탐색 방법중에서 가장 간단하고 직접적인 탐색방법
- 배열이나 연결리스트로 구현된 순차자료구조에서 원하는 항목을 찾는 방법
- 검색 대상 자료가 많은 경우에 비효율적이지만 알고리즘이 단순해 구현이 용이
1) 첫번째 원소 ~ 마지막 원소, 순서대로 키 값이 일치하는 원소가 있는지 비교/찾기
2) 키 값이 일치하는원소를 찾으면 그 원소가 몇 번째 원소인지 반환
3) 마지막 원소까지 비교하여 키 값에 일치하는 원소가 없거나 찾는 원소가 없으면 검색실패로 -1 반환

- 평균 탐색 성공 : (n+1)/2 , 평균 탐색 실패 : n번비교
- 평균 시간 복잡도 O(n), 메모리 사용 : n
- 정렬하기가 자기 구성 탐색을 사용하면 개선 가능

보초법
- 선형검색의 종료 조건은 검색할 값을 찾지 못하고 배열의 맨 끝을 지나간 경우와 검색할 값과 같은 원소를 찾는 경우로 2가지인데 단순한 판단이지만 이 과정을 계속 반복하면 종료 조건을 검사하는 비용을 무시할 수 없기에 비용을 반으로 줄이는 방법
- 검색하고자 하는 키값을 배열의 맨 끝에 저장하는데 이렇게 되면 검색할 값과 같은 원소를 발견해야 하므로 맨 끝에 도달했는지 판단은 필요하지 않으며 이 때 저장하는 값을 보초라 함

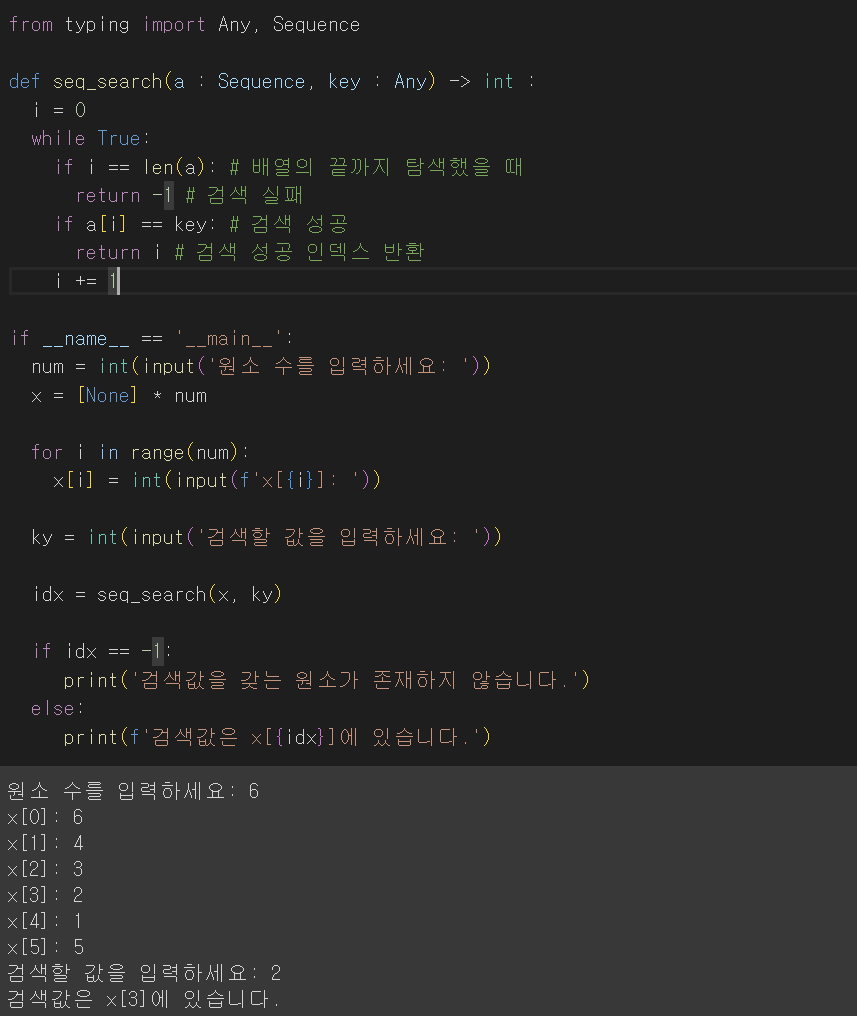
이진탐색
- 정렬된 배열의 탐색에 적합
- 배열의 중앙에 있는 값을 조사하여 찾고자 하는 항목이 왼쪽 or 오른쪽 부분 배열에 있는지를 알아 내어 탐색의 범위를 반으로 줄여서 탐색 진행
- 자료의 가운데에 있는 항목들 키 값과 비교후 다음 검색위치를 결정하고 검색을 계속 하는 방법
- 찾는 키 값 > 원소의 키 값 : 오른쪽 부분에 대해 검색을 실행
- 찾는 키 값 < 원소의 키 값 : 왼쪽 부분에 대해 검색 실행
- 키를 찾을 때까지 이진 검색을 순환적으로 반복 수행함으로써 검색범위를 반으로 줄여가면서 더 빠르게 검색
- 정복 기법을 이용한 검색 방법 -> 감색 범위를 반으로 분할 하는 작업과 검색 작업 반복 수행
- 정렬되어 있는 자료에 대해서 수행하는 검색 방법




- 순환호출을 이용하거나 반복을 이용한 구현
- 이진 검색에서 검색 범위를 반으로 분할 하고 비교하는 연산이기에 O(log2^n)
- n개의 자료에 대한 이진 검색의 메모리 사용량은 n
색인 순차 탐색(키, 주소)
- 정렬되어 있는 자료에 대한 인덱스 테이블을 추가로 사용하여 탐색 효율을 높인 검색 바업
- 인덱스 테이블 : 배열에 저장되어 있는 주 자료리스트 중에서 일정한 간격으로 떨어져 있는 원소들을 발췌하여 저장한 테이블이며 자료가 저장되어있는 배열의 크기가 n이고 인덱스 테이블의 크기가 m일 때 배열에서 n/m 간격으로 떨어져 있는 원소와 그의 인덱스를 인덱스 테이블에 저장함

- 검색 방법 : indexTable[i].key <= key <= indexTable[i+1].key를 만족하는 i를 찾아서 배열의 어느 범위에 있는지 먼저 알아낸 후 해당 범위에 대해서 순차 검색을 수행
성능
- 인덱스 테이블 크기에 따라 결정
- 인덱스 테이블의 크기가 줄어들면 배열의 인덱스를 저장하는 간격이 커지므로 배열에서 검색해야 하는 범위도 커짐
- 인덱스 테이블의 크기가 늘어나면 배열의 인덱스를 저장하는 간격이 작아지므로 검색해야 하는 범위가 작아지겠지만 인덱스 테이블을 검색하는 시작이 늘어남
- O(m(인덱스테이블 크기) + n(주자료 리스트 배열의 크기)/m)
보간탐색
- 사전이나 전화번호부 탐색 방법
- 탐색키가 존재할 위치를 예측하여 탐색, O(log2^n)
- 이진탐색과 유사하나 리스트를 불균등 분할하여 탐색

이진트리검색
- 이진탐색트리를 사용한 검색 방법
- 원소의 삽입이나 삭제 연산에 대해 항상 이진 탐색트리를 재구성하는 작업을 필요
해싱
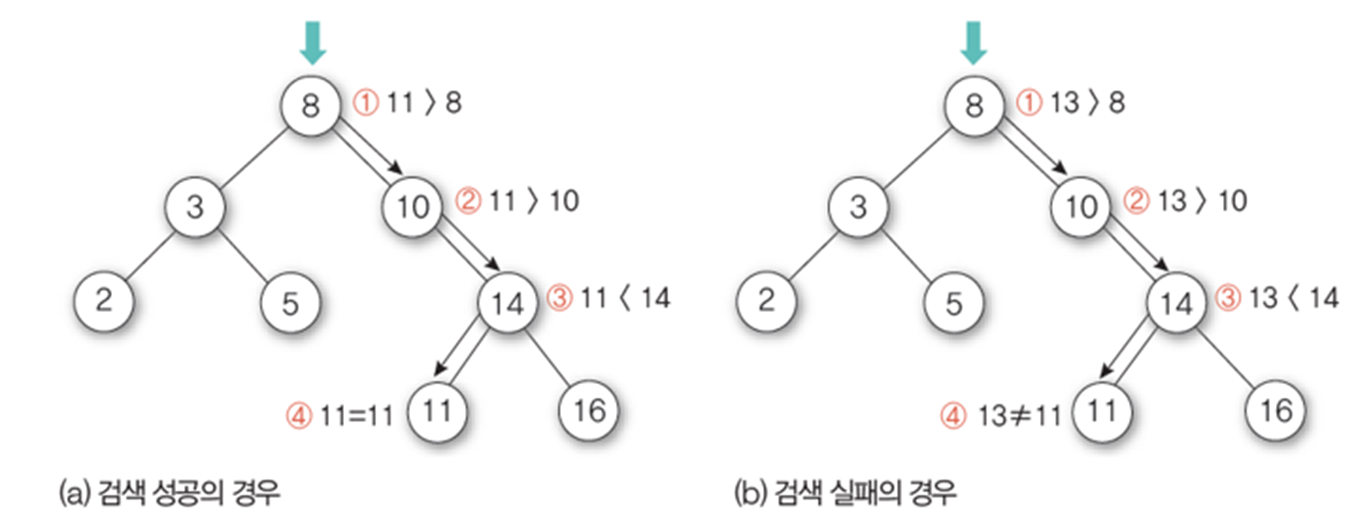
- 산술적인 연산을 이용하여 키가 있는 위치를 계산하여 바로 찾아주는 계산 검색 방식
- 키 값에 대한 산술적 연산에 의해 테이블의 주소 계산
1) 키 값에 대해서 해시 함수를 계산하여 주소를 구한다
2) 구한 주소에 해당하는 해시 테이블로 이동
3) 해당 주소에 찾은 항목이 있다면 검색 성공, 없으면 검색 실패
- 해시함수 : 키 값을 원소의 위치로 변환하는 함수 즉, 탐색키를 입력 받아 해시 주소 생성
- 해시테이블 : 해시함수에 의해 계산된 주소의 위치에 항목을 저장한 표, 키 값의 연산에 의해 직접 접근이 가능한 표
- 동거자 : 서로 다른 키 값을 가지지만 해싱 함수에 의해 같은 버킷에 저장된 키값들
- 충돌 : 서로 다른 키값에 대해서 해싱함수에 의해 주어진 버킷 주소가 같은 경우 충돌이 발생하고 비어있는 슬롯에 동거자 관계로 키값 저장
- 오버플로우 : 충돌이 슬롯수보다 많이 발생한 것으로 버킷에 비어있는 슬롯이 없는 포화 버킷 상태에서 충돌이 발생하여 해당 버킷에 키 값을 저장할 수 없는 상태
- 이상적인 해싱 : 주어진 데이터만큼 테이블 준비, 시간복잡도 O(1)
- 실제 해싱 : 해시함수 이용, 테이블의 크기를 줄이고 충돌과 오버플로가 발생, O(1)보다 떨어지는 시간복잡도를 지님
좋은 해시함수 조건
- 충돌이 적어야 한다.
ㄴ 충돌이 많이 발생한다는 것은 같은 버킷을 할당 받는 키 값이 많다는 것이므로 비어있는 버킷이 많은데도 어떤 버킷은 오버플로가 발생할 수 있는 상태가 되므로 좋은 해시 함수가 될 수 없다.
- 함수 값이 테이블의 주소 영역내에서 고르게 분포되어야 한다.
- 계산이 빨라야 한다.
- 계산이 쉬워야 한다.
ㄴ 비교 검색 방법을 사용하여 키값의 비교연산을 수행하는 시간보다 해시함수를 사용하여 시간이 빨라야 해싱검색을 사용하는 의미가 있다.
제산함수
- h(k) = k % m
ㄴ key = 10, table size = 8이라면 버킷주소는 10 % 8 = 2이다.
- 해시테이블의 크기 M은 소수 선택
폴딩함수
- 키의 비트 수가 해시테이블 인덱스의 비트수보다 큰경우 주로 사용

※ 만약 버킷이 0~999일 때 이를 초과한 값이 나온다면 0~999 안에 들어오도록 값을 만들어줘야 한다. 1018이 된다면 앞에 1을 버리고 018, 즉 버킷 주소 18에 저장한다.
중간제곱함수
- 키값을 제곱한 후 결과 같이 중간 부분에 몇 비트만을 선택하여 버킷 주소 사용
- 키를 구성하는 일부 문자가 같을지라도 서로 다른 결과값을 가질 확률이 높다
ㄴ key가 10, 7, 77, 9이고 중간 비트를 2라고 가정하게 되면 100, 49, 5929, 81에서 버킷 주소는 10, 49, 92, 81 즉 중간에서 2자리 숫자가 버킷주소가 된다.
비트추출함수
- m = 2^k일때 사용
- 탐색키를 이진수로 간주하여 임의의 위치에 k개의 비트를 해시 주소 사용
- 이 방법에서는 충돌이 발생할 가능성이 많아 테이블의 일부에 주소가 편중되지 않도록 키 값들의 비트들을 미리 분석하여 사용해야 한다.
ㄴ 20 : 1010이면 k가 2란 얘기(2^k = 4(4자릿수)), 따라서 10/01로 나눠서 해시주소로 사용
숫자분석함수
- 키 값을 이루고 있는 각 자릿수의 분포를 분석하여 해시 주소로 사용
- 키 중에서 편중되지 않는 수들을 해시테이블의 크기에 적합하게 조합하여 사용
- 각 키 값을 적절히 선택한 진수로 변환한 후에 각 자릿수의 분포를 분석하여 가장 편중된 분산을 가진 자릿수는 생략하고 가장 고르게 분포된 자릿수부터 해서 해시 테이블 주소의 자릿수만큼 차례로 뽑아서 만든 수를 역순으로 바꾸어서 주소로 사용

※ 탐색키가 문자열이라면 먼저 각 문자를 상수로 대응,
| 탐색키 | 덧셈식 변환과정(transform()) | 덧셈합계 | 해시주소 |
| do | 100+111 | 211 | 3 |
| for | 102+111+114 | 327 | 2 |
| if | 105+102 | 207 | 12 |
| case | 99+97+115+101 | 412 | 9 |
| else | 101+108+115+101 | 425 | 9 |
| return | 114+101+116+117+114+110 | 672 | 9 |
| function | 102+117+110+99+116+105+111+110 | 870 | 12 |
- a : 97로 두고 알파벳 순서대로 1씩 증가, 해시주소는 알파벳 길이로 나눈 값, 211 // 26 = 3
오버플로 처리방법
- 개방주소법 : 주소를 개방해 해시테이블의 다른 주소에서 처리할 수 있도록 허용, 선형조사법이라고도 함
ㄴ 충돌이 일어난 항목을 해시 테이블의 다른 위치에 저장
ㄴ 해싱함수로 구한 버킷에 빈 슬롯이 없어서 오버플로 발생, 그 다음 버킷에 빈 슬롯이 있는지 조사
ㄴ 적재밀도범위 0~1
ex) 만약 충돌이 ht[k]에서 발생했다면 ht[k+1]이 비어있는지 조사하고 비어있지 않다면 ht[k+2]조사한다. 비어있는 공간이 나올 때까지 계속 조사하다 테이블의 끝에 도달하게 되면 테이블의 처음부터 조사하고 시작했던 곳으로 다시 돌아오게 되면 테이블은 가득 찬 것이다.
| 버킷 | 1단계 | 2단계 | 3단계 | 4단계 | 5단계 | 6단계 | 7단계 |
| [0] | function | ||||||
| [1] | |||||||
| [2] | for | for | for | for | for | for | |
| [3] | do | do | do | do | do | do | do |
| [4] | |||||||
| [5] | |||||||
| [6] | |||||||
| [7] | |||||||
| [8] | |||||||
| [9] | case | case | case | case | |||
| [10] | else | else | else | ||||
| [11] | return | return | |||||
| [12] | if | if | if | if | if |
- do = 211이고 211을 M으로 나누면 211 % 13 = 3이므로 3에 do 저장
- 이런식으로 하게 되면 군집화 현상이 발생한다.
군집화 현상 완해하는 방법
1) 이차조사법
ㄴ 선형조사법과 비슷하지만 다음 조사할 위치를 아래 식 사용
ㄴ (h(k) + i*i) % M -> h(k), h(k)+1, h(k)+4 ....
ㄴ 군집과 결합 크게 완화 가능
2) 이중해싱법
ㄴ 재해싱이라고도 하며 오버플로가 발생하면 다른 별개의 해시함수를 사용
ㄴ step = C - (k % C) -> h(k), h(k)+step, h(k)+2*step



다른 오버플로 처리방법
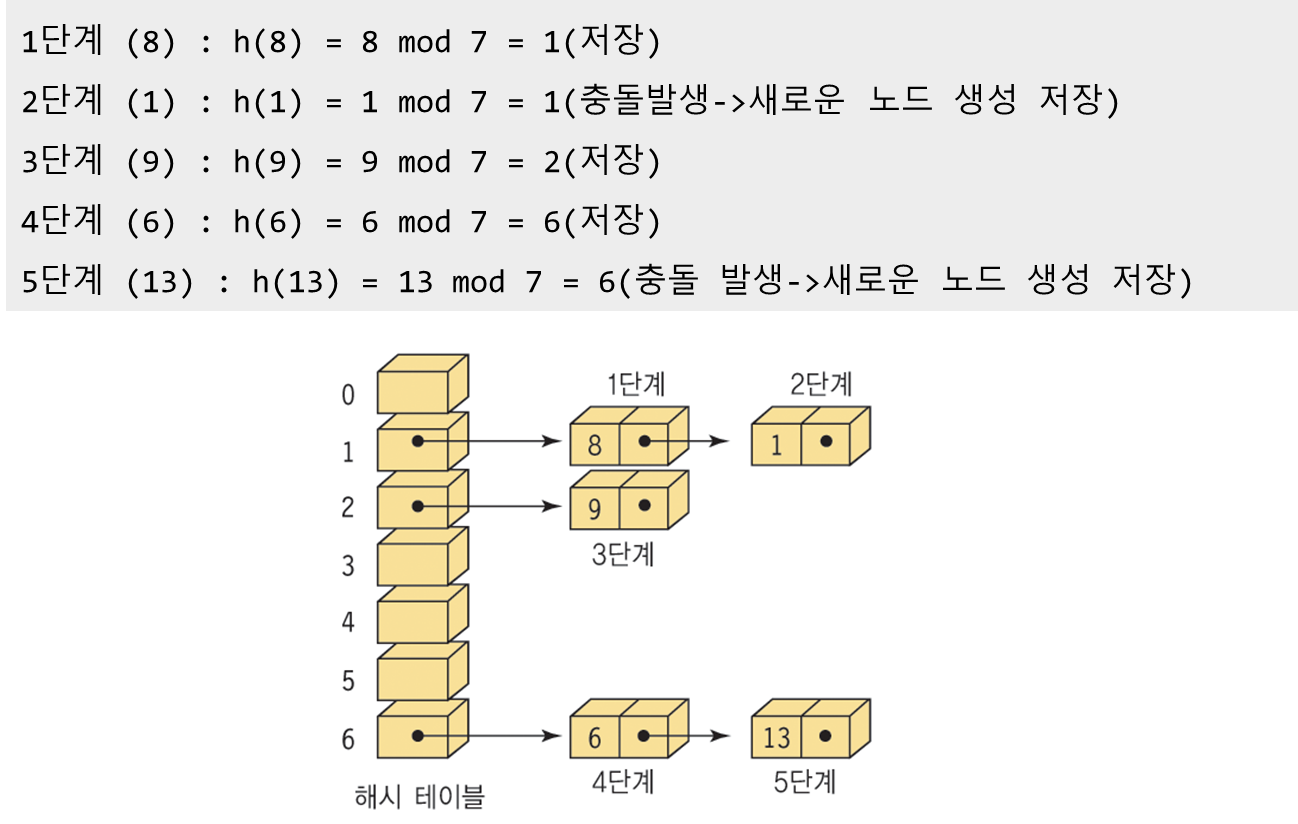
- 체이닝
ㄴ 해시테이블의 구조를 변경하여 각 버킷에 하나 이상의 키 값을 저장할 수 있도록 하는 방법
ㄴ 각 버킷에 삽입과 삭제가 용이한 연결리스트 할당
ㄴ 각 버킷에 대한 헤드 노드는 1차원 배열로 만들로 각 버킷에 대한 헤드 노드는 슬롯들을 연결리스트로 가지고 있어서 슬롯의 삽입과 삭제가 쉽게 가능
ㄴ 버킷 내에서 원하는 슬롯을 검색하기 위해선 버킷의 연결리스트를 선형검색
ㄴ 각 버킷에 고정된 슬롯이 할당되어 있지 않다


- 적재밀도 또는 적재비율
ㄴ 저장되는 항목의 개수 n과 해시 테이블의 크기 m에 대한 비율


사진 출처:
쉽게 배우는 C 자료구조 | 생능출판사
코딩을 조금이라도 해 보았다면 프로그래밍이 자료(data)를 주로 다루는 것임을 알 수 있을 것이다. 우리가 프로그램을 개발할 때 가장 먼저 해야 할 일은 처리할 자료를 컴퓨터가 잘 다룰 수 있
www.booksr.co.kr



